
Замрите…. Снято!
О технологии создания и использования Snapshot в системах хранения данных
Одно из основных преимуществ дисковых RAID массивов – надежность хранения данных. В первую очередь она обеспечивается на аппаратном уровне путем использования дополнительного диска (дисков) для записи контрольной информации, достаточной для восстановления данных при выходе в массиве из строя одного (при уровнях RAID 3 или 5) или даже нескольких ( RAID 6, 6+) жестких дисков. Кроме того, во внешних RAID массивах предусматриваются избыточные (допускающие замену в "горячем", т.е. без выключения питания режиме) блоки питания и вентиляторы охлаждения. Возможна установка дополнительных батарей питания кэш-памяти, обеспечивающих защиту и хранение ее содержимого (информации, которая не успела записаться на жесткие диски массива) при аварийном отключении питания. Кроме этого, в критичных к непрерывной работе областях применения современных систем хранения данных используется по 2 независимых RAID контроллера, дублирующих обработку данных. И все это с одной целью – обеспечить сохранность важных данных при любых аппаратных сбоях используемой системы хранения. Тем не менее, надо заметить, что 100% уверенность в сохранности данных может дать только дублирование систем хранения с соответствующей поддержкой со стороны используемого программного обеспечения.
Однако существуют опасности другого рода, от которых эти всевозможные аппаратные ухищрения не спасут: вирусы, сбои программ, да и просто человеческие ошибки, приводящие к потере данных. Наконец, не исключены стихийные бедствия, грозящие физическим уничтожением систем вместе со всей информацией. Единственная защита от таких ситуаций – резервное копирование данных (часто называемое бэкап – от английского backup). При этом резервные копии есть смысл сохранять исключительно на иных, чем источник копии, аппаратных устройствах. В идеале копия должна быть максимально удалена географически от оригинала, во избежание ее утери в случае серьезной техногенной катастрофы. Несмотря на простую, на первый взгляд, задачу – скопировать данные для их сохранности, решить ее технически грамотно позволит не всякое оборудование/программное обеспечение.
Проблема в том, что чаще всего приходится создавать архивные копии данных, которые постоянно изменяются, и период времени, который занимает само копирование, исключением не бывает. Понятно, что ценность копии, которая изменялась в процессе копирования, невелика – данные, копируемые в начале могут измениться и не соответствовать данным к концу копирования. К сожалению, механизма мгновенного копирования в природе пока не существует и вряд ли когда-нибудь такой способ будет существовать. Кроме этого, работающее приложение может заблокировать отдельные файлы и не дать их скопировать в принципе. Решение всех этих проблем и потребовало создание специального механизма – snapshot (снапшот, в простом переводе – моментальный снимок). Этот механизм существует как в аппаратной реализации в системах хранения корпоративного уровня, так и в программной и программно-аппаратной. Типичный пример программного механизма создания "моментальных снимков" - сервис Volume Shadow Copy Service (сокращенно - VSS), который встроен во все операционные системы от Microsoft, начиная с Windows XP.
Идея снапшота довольно проста – по команде программы или человека данные как бы "замораживаются" и могут затем оставаться таковыми сколь угодно долго. В реальности программа или оборудование создают фактически виртуальный диск, на котором находятся не сами данные, а ссылки на них. Тем не менее, с точки зрения программ архивирования снапшот представляет собой полноценный диск с данными, который можно спокойно копировать, не боясь, что данные за время копирования будут изменены.
Попробуем кратко рассказать о том, как, собственно, работает механизм создания снапшотов. Для начала представим себе такую систему, в которой данные записываются параллельно и одновременно на два диска: основной и дублирующий. Такой вариант работы с данными часто называют "зеркалированием" данных. Теперь представим себе, что в некоторый момент времени мы перестаем писать на дублирующий диск, а пишем только на основной. В результате в нашем распоряжении появляется резервная копия данных на вспомогательном диске, соответствующая времени прекращения записи на дублирующий диск. Это и есть Snapshot. Далее можно не торопясь создать копию содержимого дублирующего диска.
Конечно, это упрощенное и утрированное описание идеи снапшота. В реальности это организовано несколько иначе. Поскольку команда на создание снапшота может поступить в любой момент, и снапшот сразу же должен быть готов к копированию, то на дублирующем диске хранятся не сами данные, а только ссылки на них с основного диска. В таком варианте снапшот рассматривается как копия неких мета-данных в специально отведенной (резервной) области. Это означает, что сами данные никуда не копируются, копируются только ссылки на данные (или, для простоты понимания - каталог). Этот вариант также называется PIT (point-in-time) копией исходных данных. Далее, если приложение пытается перезаписать исходные данные, то соответствующая программа сначала копирует блок подлежащих изменению оригинальных (исходных) данных на новое место (в специальную область, выделенную для операций копирования), и только потом выполняет собственно операцию записи. Значения ссылок соответственным образом обновляются. Такая технология называется COW (copy-on-write) и ее идея иллюстрируется на рисунке ниже.
|
|
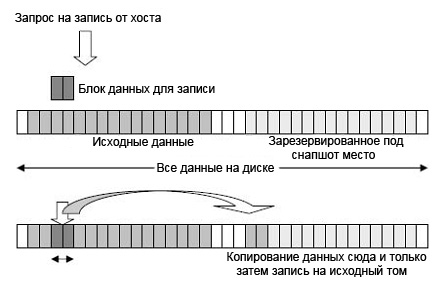
При таком подходе к созданию snapshot он уже не представляет собой физическую копию исходных данных, он представляет собой своеобразную логическую копию исходного тома. Разумеется, при этом он всегда сохраняет связь с исходным томом, а внешними серверами видится как отдельный том. При использовании технологии COW эта логическая копия исходных данных занимает меньший, чем сами данные, объем дискового пространства. Более того, при начальном создании такого снапшота никакие данные вообще никуда не копируются (только создается копия каталога данных с указателями на места их хранения). Соответственно, этот процесс происходит практически мгновенно. И только когда данные изменяются в исходном томе, то их старое значение перемещается в зарезервированную для таких данных область. Когда же компьютер выдает запрос на чтение снапшота, то всегда извлекаются данные, "замороженные" в заданное время, вне зависимости от последующих операций различных приложений с этими данными. В случае необходимости восстановление данных из снапшота происходит с той же скоростью, что и архивирование, поскольку не измененные после "съемки" данные просто остаются на своих местах, а измененные данные копируются на свои старые места.
Достоинства столь простого способа создания снапшотов очевидны:
Во-первых, мы получаем копию практически мгновенно – копирование ссылок на данные (правильнее – каталога) занимает доли секунды.
Во-вторых, копируется весь каталог, включая ссылки на открытые файлы. Напомним, что файлы, открытые и заблокированные различными приложениями, скопировать стандартными средствами нельзя. Разумеется, далеко не факт, что при восстановлении данных удастся использовать заблокированные (незакрытые) файлы, но пусть лучше они будут, чем нет.
В-третьих, в данном варианте создание snapshot может быть реализовано аппаратно, силами RAID контроллера дискового массива. Это означает, что для компьютеров, подключенных к системе хранения, процесс создания снапшота будет незаметен, т.е. снижения производительности компьютеров не будет.
После того, как виртуальным томам или snapshot-томам назначены ID/LUNs (Logical Unit Number), компьютер видит каждый снапшот (если их несколько) как физический диск. Тем самым со снапшотами могут производиться те же действия, которые могут производиться и с обычными дисками.
К сожалению, не все так радужно в создании и применении снапшотов, как хотелось бы. Основная проблема в том, что полученный snapshot фактически представляет собой копию данных весьма сомнительной полезности, поскольку мы как бы внезапно выключили компьютер и тем самым "заморозили" данные. Вполне возможно, что файлы, которые только начали создаваться, безвозвратно утеряны. Для файлов, содержимое которых должно быть измениться на диске, RAID контроллер не успел переписать все данные из своей кэш-памяти на диск и эти файлы вообще представляют собой абстрактный набор данных, что еще хуже просто потерянных данных. Иными словами, снапшоты можно использовать, строго говоря, только в тех случаях, когда мы можем быть уверены в результате, т.е. целостности данных на момент "снимка". Самый простой вариант решения этой проблемы – завершить (остановить) работу всех приложений, использующих диск, снапшот с которого нам нужен, сделать "снимок", а затем снова запустить (возобновить работу) приложения.
Многие программы архивирования данных решают эту задачу довольно просто – на компьютер с приложением, данные которого надо периодически сохранять, ставится специальная программа, обычно называемая агентом, которая по специальной команде от программы архивирования "замораживает" данные в целостном состоянии. В качестве примера таких программ – Symantec Backup Exec, Computer Associates ARCserve® Backup. Разумеется, такие агенты существуют только для конкретных программ и они не охватывают, да и не могут охватить все разнообразие применяемого программного обеспечения. Особенно это относится к не- Windows ОС, для которых таких агентов крайне мало. Именно поэтому программные агенты не являются панацеей и наилучшее соотношение затраты/результат дает применение совместно программного и аппаратного решения. Например, снапшот умеет создавать сама система хранения данных, но команду на создание система хранения получает от программы-агента, установленной на компьютере.
Поддержка снапшотов в системах хранения данных от компании Maxtronic
Сама по себе реализация snapshot в системах хранения от Maxtronic International выполнена по вышеописанной схеме – снапшот создается как каталог ссылок на исходные данные, а все перезаписываемые данные сбрасываются с помощью COW на диск со снапшотом. Единственное существенное отличие в том, что вы можете дополнительно создать специальный COW-том, который не виден никому, но который может быть использован в том случае, если не хватает места на любом из снапшот-томов.
Перед созданием snapshot-копий для рабочего тома необходимо создать другой том (вторичный), связанный с рабочим томом (первичным), т.е. сформировать пару для Snapshot. Сами же snapshot-копии создаются на вторичном томе.
После того, как первоначальная snapshot копия создана, команды записи данных на первичный том вызовут выполнение операции "copy-on-write" (COW), т.е. копирование старых данных с первичного тома на вторичный перед записью новых данных на первичный том.
Snapshot-том (диск) – это виртуальный объект, который, как уже упоминалось выше, представляет собой ссылки на исходные данные. Когда необходимо чтение данных с Snapshot-тома, то данные берутся с первичного тома, если они не обновлялись, или с вторичного тома, если данные были изменены. Поскольку вторичный том хранит только отличающиеся данные, при начальной настройке Вы можете задавать размер вторичного тома в разы меньше, чем размер первичного тома. Однако не рекомендуется задавать размер вторичного тома менее 10 процентов от размера первичного тома, поскольку ссылки тоже занимают место, да и перезаписываемые данные требуют места для своего размещения. Пользователь может настроить службу оповещения системы хранения, потребовав сообщить ему об угрозе нехватки места под снапшоты. Конечно, учитывая дешевизну дисковой емкости, правильнее всего не экономить и создавать пары равного объема.
Первичному тому может соответствовать множество Snapshot-томов (копий), каждая для своего момента времени. При этом они будут храниться на единственном вторичном томе. На рисунке показаны соотношения первичного, вторичного томов, и Snapshot-томов. Заметим, что при наличии нескольких snapshot операция COW будет приводить к уменьшению быстродействия системы хранения. Поскольку снапшотов может быть много, то выполнение COW для разных снапшотов будет отнимать ресурсы системы хранения из-за разбросанности снапшотов по диску. Чем к большему количеству исходных данных для snapshot-томов будут запрашиваться обращения по записи в одно и то же время, тем больше будет снижаться быстродействие системы хранения от применения COW процедуры.
Процесс создания snapshot можно условно разделить на три этапа:
Этап 1: Проектирование (Планирование)
-
Определить том-источник, для которого необходимо создать Snapshot.
-
Определить количество snapshot и время их существования.
-
Определить дисковое пространство и конфигурацию RAID для вторичного тома.
-
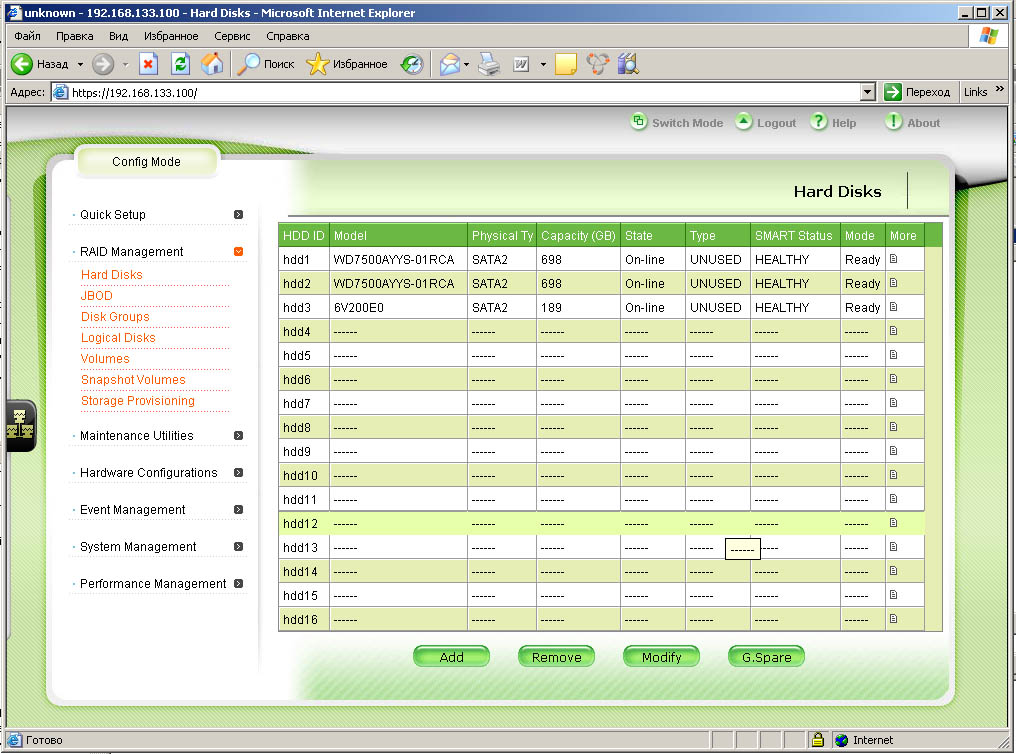
Задать LUN’ы на снапшот-тома и сделать эти LUN видимыми для тех компьютеров, которым это требуется (например, для архивирования снапшотов). При этом надо учесть, что snapshot том будет иметь с точки зрения операционной системы компьютера те же параметры, что и исходный том, поэтому во избежание противоречий snapshot том не должен быть виден компьютеру, который работает с исходным томом.
Наглядно эти этапы можно видеть на иллюстрациях ниже. В данном примере мы использовали 3 диска. На 2 дисках по 750 GB будет создан RAID 0, а отдельный диск (JBOD) так таковым и останется. Для получения любой картинки в исходном разрешении просто щелкните на изображении.
 |
|
Начало большого пути - исходное состояние |
|
|
| Создаем дисковую группу dg0 из двух дисков по 750 GB |
|
|
| Создаем логический диск dg0ld0 |
 |
| Назначаем lun0 ранее созданному dg0ld0 и мапируем lun0 на первый FC порт |


Этап 2: Конфигурация
-
Создать дополнительные тома в случае необходимости создания снапшотов для нескольких первичных (исходных) дисков.
-
Выбрать вторичные тома для каждого исходного тома (первичного тома)
-
Задать пороговые значения на заполнение вторичных томов, в случае превышения которых система хранения должна сообщить нам об угрозе переполнения.
-
Задать сценарии автоматизации создания snapshot (дополнительно).
Иллюстрации:
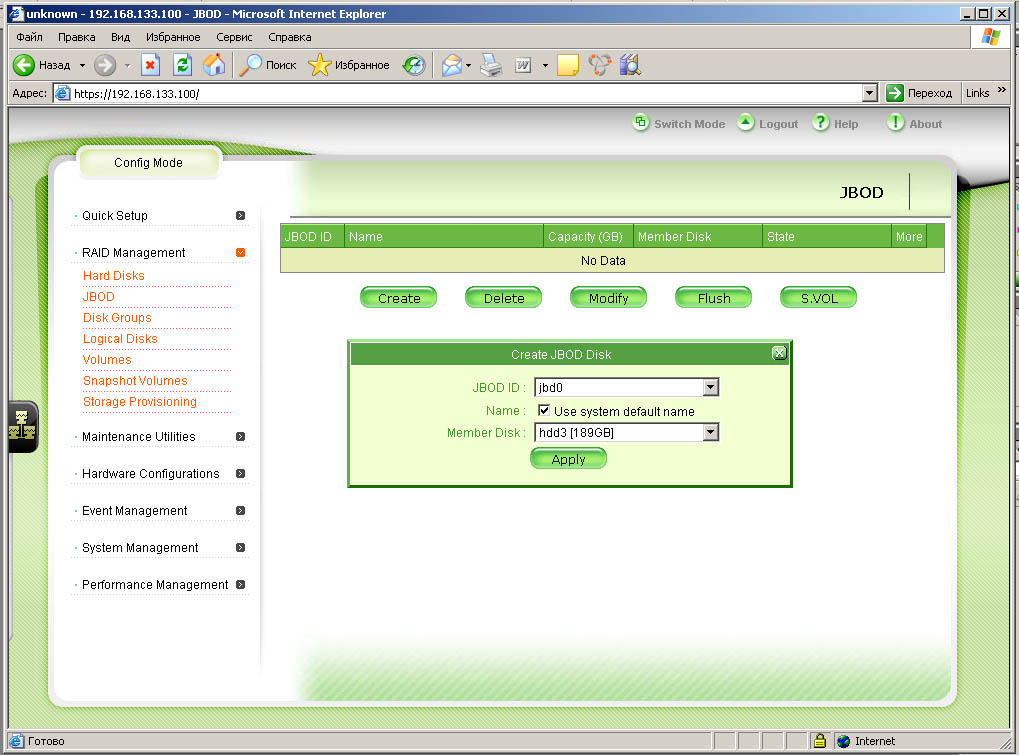 |
| Создаем логический диск jbod0, который затем будем использовать для хранения снапшотов |
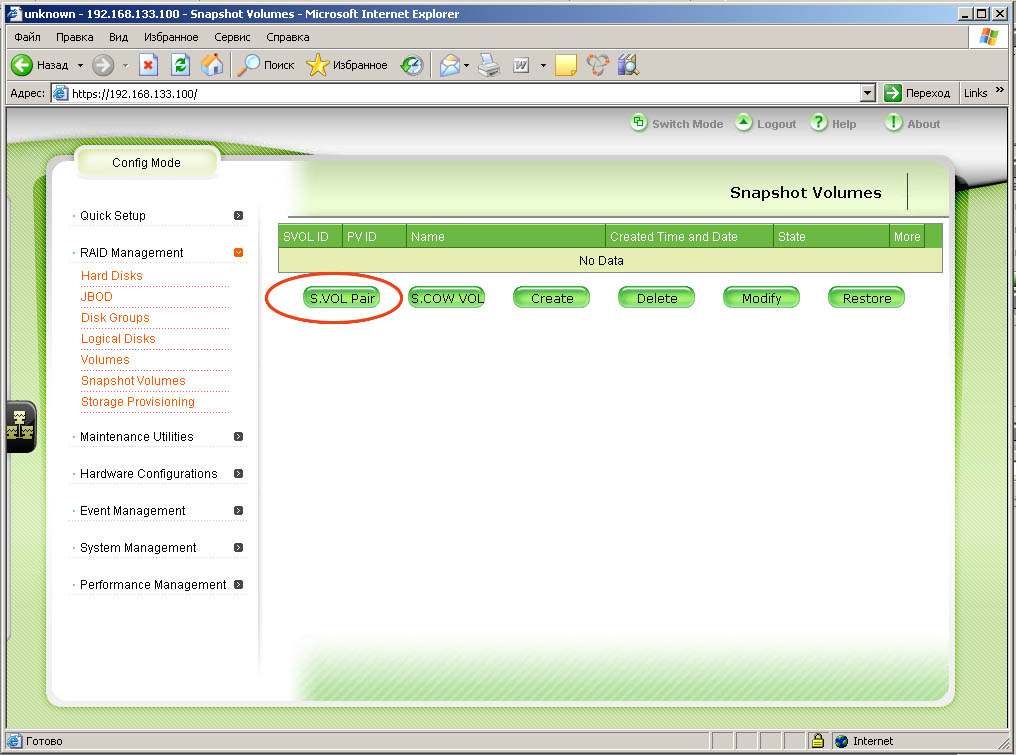 |
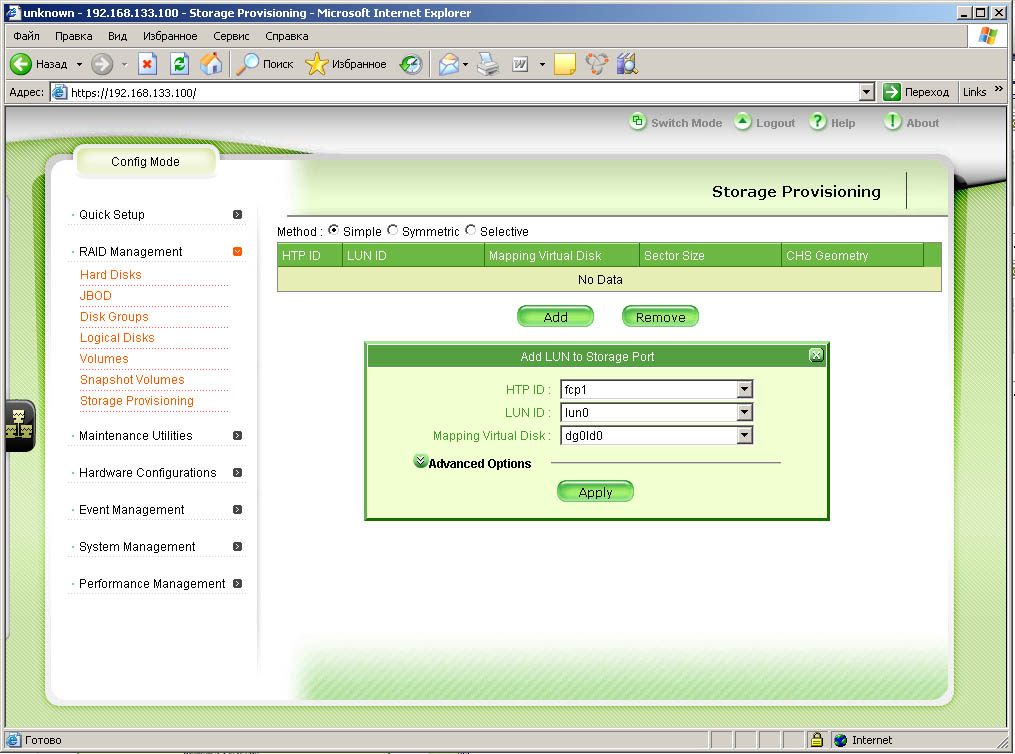
| Мы готовы к созданию пары томов - исходного в паре с томом под снапшот. Просто нажимаем кнопку S.VOL Pair |
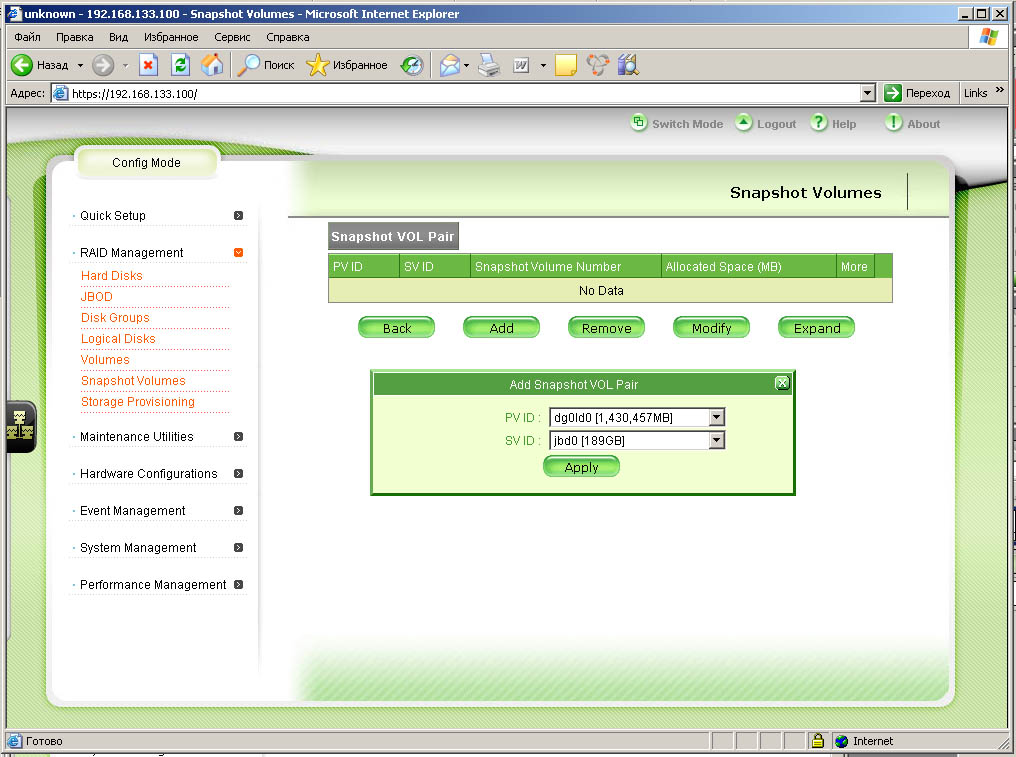 |
| Создаем пару томов в связке из dg0ld0 и jbod0 |
Этап 3: Создание и использование Snapshot (Вручную или по сценарию)
При создании Snapshot для исходного тома, требуется:
9. Остановить все операции записи на первичный (исходный) том
10. Очистить кэш-память компьютера (компьютеров), который работает с данным томом.
11. Создать Snapshot.
12. Разрешить доступ на запись к первичному (исходному) тому.
13. Скопировать данные со Snapshot-тома в другое место для архивирования в случае необходимости (дополнительно)
14. Удалить snapshot-том, если он более не нужен – например, он скопирован в архив (дополнительно), чтобы избежать заполнения вторичных томов.
Действия на этапах 1 и 2 выполняются только один раз, когда настраиваете систему хранения или когда создаете новый LUN. Они также могут выполняться при переконфигурировании системы хранения. Действие на этапе 3, очень вероятно, будет периодически повторяться, когда необходимо создать новый Snapshot.
И снова немного иллюстраций процесса:
 |
| Мы готовы к созданию снапшота |
 |
| Нажимаем кнопку Create и создаем снапшот с именем svol0 |
 |
| Снапшот создан |
 |
| Назначаем lun1 ранее созданному снапшоту svol0 и мапируем lun1 на первый FC порт |
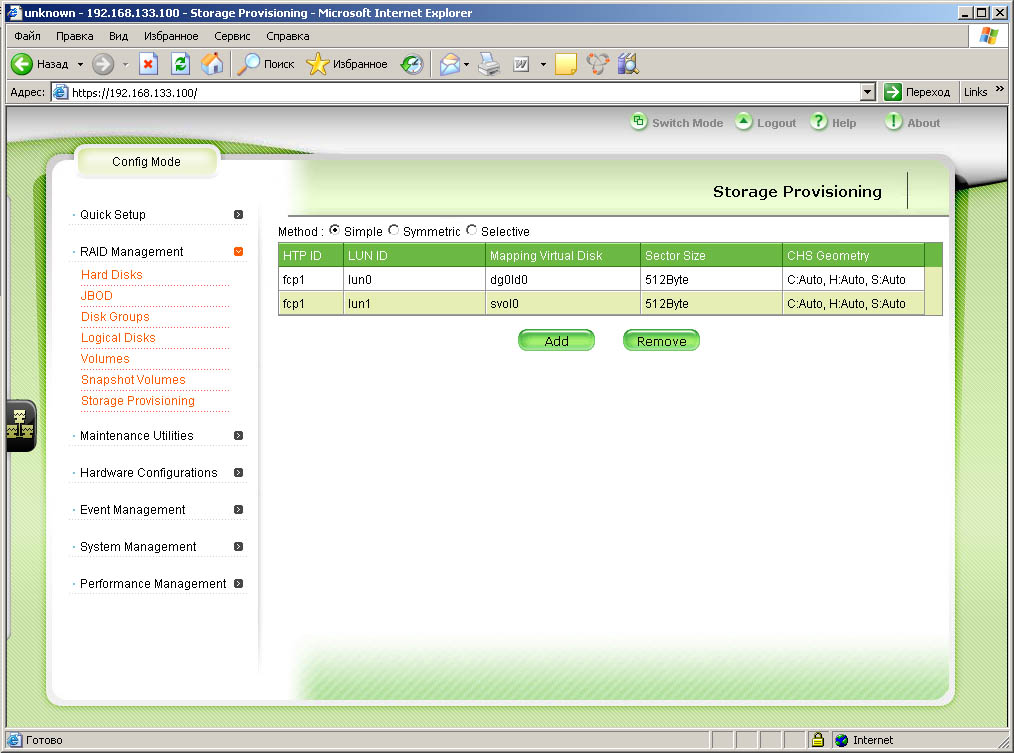 |
| Теперь с точки зрения внешнего мира у нас два диска - один оригинальный и один снапшот |
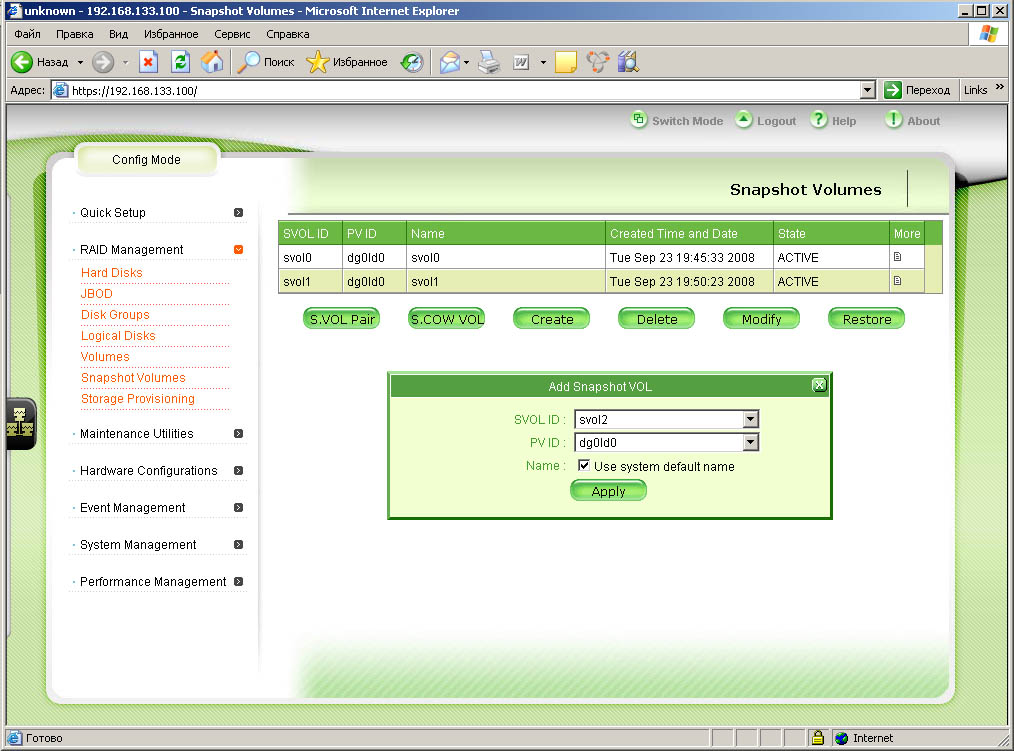 |
| Создадим еще пару снапшотов svol1 и svol2 |
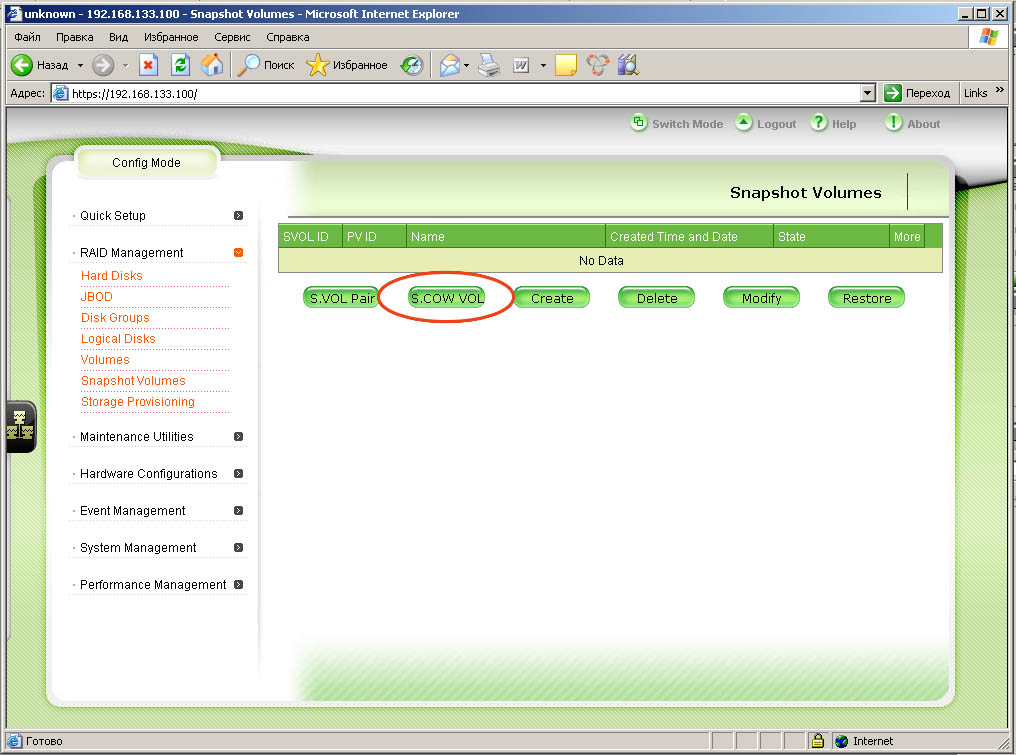 |
| Если вы опасаетесь, что места на снапшот томе может не хватить, вы простым нажатием на кнопку S.COW VOL можете создать специальный невидимый внешнему миру том, который будет использоваться для хранения перезаписываемых данных для всех снапшотов |
Все процедуры, описанные нами на этапе 3, выполнялись вручную. Разумеется, в реальной работе создание снапшота таким образом вряд ли будет нужно кому-либо. Поэтому правильнее всего применять процедуру создания снапшота по расписанию. Достаточно скачать специальную программу для управления снапшотами и настроить планировщик задач Windows для запуска программы и тем самым создания/удаления снапшот в нужное время. Например, для бэкапа данных Microsoft SQL Server можно применить такую последовательность действий
1. Net stop mssqlserver; Работа SQL Server остановлена
2. rcmd 192.168.0.1 C:snapshotacs_snap flush D: ; На компьютере с адресом 192.168.0.1 запускается программа acs_snap (о которой шла речь выше), по команде flush очищается кэш системы хранения
3. rcmd 192.168.0.1 C:snapshotacs_snap create D: sql_shot; Создается снапшот
4. Net start mssqlserver; Работа SQL Server возобновлена
Далее, с помощью скрипта, используя интерфейс командной строки (CLI) системы хранения и режим командной строки Windows:
5. Назначается LUN созданному снапшоту
6. На бэкапном сервере с помощью команды mountvol подмонтируется том снапшота
7. Запускается программа копирования снапшота
8. rcmd 192.168.0.1 C:snapshotacs_snap delete D: sql_shot; Ранее сохраненный снапшот удаляется